Have I mentioned how important I think it is for a linter to have great docs? Well, now is the time for Curlylint to live up to this!
New documentation format for rules
Up until now the rules’ documentation was pretty sad, essentially limited to what could fit in the project’s README. Now… take a look:
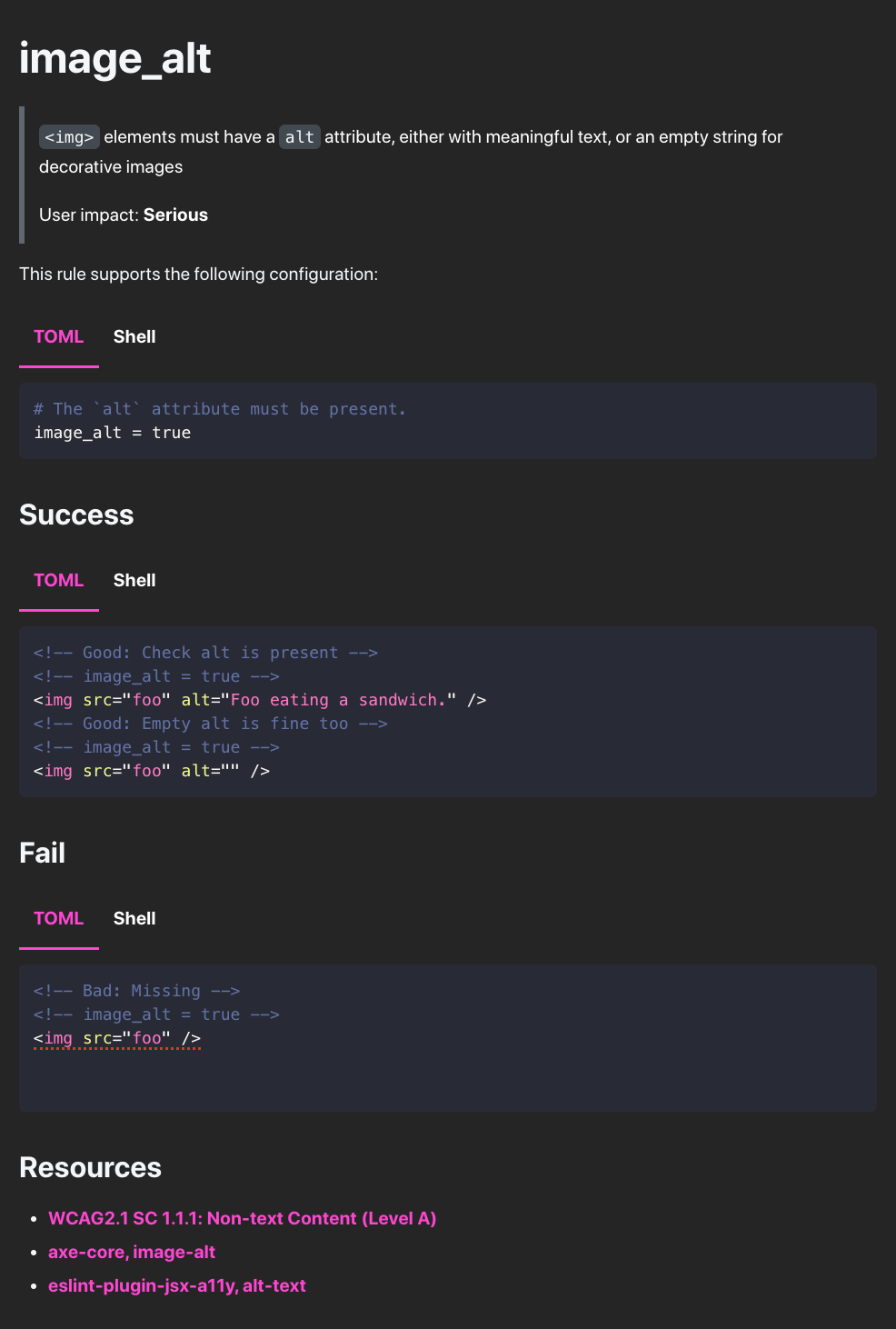
- The rule’s different configuration options are clearly visible, copy-pasteable, each with a description.
- Cases where the rule check “succeeds” are well documented, alongside a comment, and matching configuration.
- Same for problematic cases, which even show the actual error message!
- All of this is toggle-able between the different configuration formats supported by Curlylint!
- There are follow-up resources available for developers who want more information about the rule.
This feels like a pretty big step up compared to the previous documentation, and should hopefully make it as easy as possible for people to start using the linter for their templates.
How this works
The majority of the rules’ documentation is generated from their metadata:
JSON Schema
The configuration options are all defined with JSON Schema.Currently this is only used to generate the documentation, but in the future I would also like to make this validate configurations as Curlylint runs.
JSON Schema is particularly good for this because it has built-in support for the schema to be self-documenting – adding titles, descriptions, and examples, which are all used to generate the documentation. Here is the schema of the html_has_lang rule as an example:
{
"oneOf": [
{
"const": true,
"title": "The `lang` attribute must be present.",
"examples": [true]
},
{
"type": "string",
"title": "The `lang` attribute must match the configured language tag.",
"examples": ["en-US"]
}
]
}
Test cases
The success / fail sections are simply coming from the project’s test suite! I always prefer to invest time writing extensive unit tests for projects of this kind. Some of the test cases simply have a flag marking them as “documentation examples”:
{
"label": "Check lang is present",
"template": "<html lang=\"en\"></html>",
"example": true,
"config": true,
"output": []
}
It’s the same story for “fail” cases, where the annotations are simply generated from the expected output (issues):
{
"label": "Missing",
"template": "<html></html>",
"example": true,
"config": true,
"output": [
{
"file": "test.html",
"column": 1,
"line": 1,
"code": "html_has_lang",
"message": "The `<html>` tag should have a `lang` attribute with a valid value, describing the main language of the page"
}
]
}
MDX
All of this comes together with MDX, a Markdown-inspired syntax which makes it possible to use JSX directly inside documents, thereby making it possible to use React components, like the language tabs and code snippets with annotations:
<Tabs
groupId="config-language"
defaultValue="toml"
values={[
{ label: "TOML", value: "toml" },
{ label: "Shell", value: "shell" },
]}
>
<TabItem value="toml">
<CodeSnippet
snippet={`# The \`alt\` attribute must be present.\nimage_alt = true`}
annotations={[]}
lang="toml"
/>
</TabItem>
<TabItem value="shell">
<CodeSnippet
snippet={`# The \`alt\` attribute must be present.\ncurlylint --rule 'image_alt: true' .`}
annotations={[]}
lang="shell"
/>
</TabItem>
</Tabs>
Docusaurus supports MDX out of the box, and provides the “Tabs” components. The CodeSnippet component is originally from Docusaurus but has been customized to support basic annotations.